Analizando logs en 5 minutos con ELK
A partir de una idea de Santiago, y tomando como base algunos componentes que los muchachos de MercadoLibre utilizan para su infraestructura de gestión de logs, se me ocurrió hacer una prueba de concepto de a lo que es posible arribar rápidamente utilizando la tríada ElasticSearch + Logstash + Kibana, más conocida com ELK.
Para dar una mínima introducción, diremos que ElasticSearch es un motor de búsqueda RESTful basado en el archiconocido Lucene, Logstash es una especie de concentrador/manipulador/estandarizador de logs provenientes de múltiples fuentes, y Kibana es un visualizador de eventos que corre enteramente en el navegador. Los tres son componentes que pueden utilizarse en forma separada, pero en conjunto aplican precisamente esto de que el todo es más que la suma de las partes. De hecho yo había estado viendo Logstash aparte para una charla sobre logging que diera algunos años atrás, cuando aún era un proyecto incipiente, y ahora me encuentro con que es un proyecto ampliamente utilizado en un montón de lados.
Pero hoy no quiero detenerme demasiado en la teoría; la idea de este post es analizar registros yendo de 0 a 100 en 5 minutos (o lo que tarde en bajar cada aplicación) y para ello nada mejor que arrancar ahora. Así que…
Analizando logs en 5 minutos con ELK
Prerrequisitos
Como prerequisito es necesario el motor de ejecución java 1.6 o 1.7. En distribuciones basadas en debian alcanza con instalar openjdk-6-jre u openjdk-7-jre. O eso creo, a lo mejor es necesario el jdk también; prueben por las dudas. El resto de los pasos se pueden hacer sin necesidad de ser root, como usuario común.
Paso 0. Ubicarnos en un directorio limpio
mkdir elk cd elk
Paso 1. Obtener logstash
wget -c https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz tar zxf logstash-1.4.2.tar.gz
Paso 2. Obtener elasticsearch
wget -c https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.1.1.tar.gz tar zxf elasticsearch-1.1.1.tar.gz
Paso 3. Obtener un log de apache
… de algún lado. Si tienen un apache a mano, cópiense el archivo al directorio actual y dénle permisos de lectura para su usuario
cp /var/log/apache2/access.log access.log chmod go+r access.log
O si no tienen ninguno a mano, acá les dejo uno que es un fragmento del log de este mismo sitio. Ustedes pueden hacer lo que les plazca con él, total este es un blog personal. Si quieren optar por otra alternativa, google hacking es su amigo y yo no se los recomendé.
wget -c http://maurom.com/files/access.elk.log -O access.log
Paso 4. Iniciar elasticsearch
echo Iniciando Elasticsearch. Aguarde 15s ... elasticsearch-1.1.1/bin/elasticsearch & sleep 15
Paso 5. Crear un archivo de configuración para parsear logs de apache
Para ello, creen un archivo de texto llamado logstash-apache.conf en el directorio actual y copien y peguen el siguiente bloque. Luego editen la ruta al archivo de logs, indicándola en forma absoluta, y configuren el tipo de entradas de log y el lenguaje de los meses según corresponda (sino tira unos errores horribles).
input {
file {
# apuntar a donde haga falta, con ruta absoluta!
path => "/home/usuario/elk/access.log"
# desde donde leer el log ("end" para tomar datos en vivo)
start_position => beginning
}
}
filter {
if [path] =~ "access" {
mutate { replace => { "type" => "apache_access" } }
grok {
# depende del formato de archivo
match => { "message" => "%{COMBINEDAPACHELOG}" }
# match => { "message" => "%{COMMONAPACHELOG}" }
}
kv {
# con esto parsea incluso querystrings
source => "request"
target => "params"
field_split => "?&"
}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
# si los meses estan en ingles, u otro lenguaje en tal caso
locale => "en"
}
}
output {
elasticsearch { host => localhost }
# salida estandar coloreada, util para debug
#stdout { codec => rubydebug }
}
Todo este archivo tiene su lógica según la documentación de logstash.
Paso 6. Iniciar logstash+kibana con la configuracion dada
echo Iniciando Logstash. Aguarde 15s ... logstash-1.4.2/bin/logstash -f logstash-apache.conf -- web & sleep 15
Paso 7. Levantar un navegador web
xdg-open "http://localhost:9292/index.html#/dashboard/file/logstash.json"
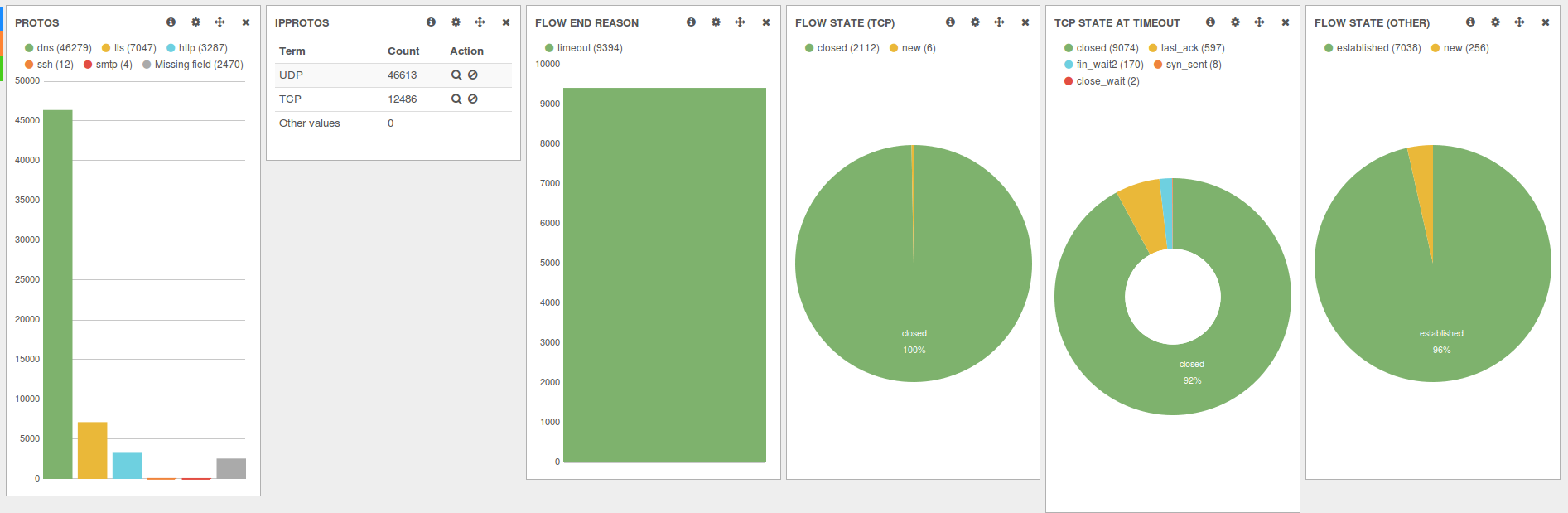
Paso 8. Jueguen con los filtros, los gráficos y deléitense con la visualización.
Fíjense de qué epoca son las entradas del log, pues puede que tengan que modificar algunas cosas para que Kibana les encuentre los eventos para esas fechas. Por ejemplo, el log de apache que les pasé solo tiene entradas para el mes de julio de 2014, así que seleccionen ese rango en el filtro de fechas de Kibana.
Acá les dejo algunas capturas de lo que pueden llegar a hacer, que si bien no son de análisis de apache, dan una idea de las posibilidades:


Paso 9. Terminar la tarea
Para cerrar los procesos, matelos sanamente con kill PID a cada proceso java asociado.
Ah, y una mención antes de terminar: cada vez que logstash procesa un archivo, anota hasta donde leyó para no volver a cargar la información, por lo que si están jugando con la configuración van a tener que borrar unos archivos .sincedb_algo que genera en el directorio $HOME del usuario para que vuelva a recorrer el mismo log.
Por último, en este caso estamos parseando son entradas de accesos a un sitio web, pero el combo ELK puede procesar casi cualquier tipo de flujo de eventos, y si bien java mucho no me atrae, todo este paquete vale la pena; piensen cuanto habrían tardado en programar ustedes una interfaz tan flexible y completa…
Como sé que ustedes son tan haraganes como yo, acá tienen todo en un solo script que lo hace de una.
Si se quedaron manija, acá van algunas demos y algo de documentación:
- Introduction and Demo to the Elasticsearch, Logstash and Kibana (YouTube)
- Cómo lo usan los muchachos de MercadoLibre (Slides)
- Introducción a ELK (Elasticsearch, Logstash y Kibana) (parte 2)
- How To Use Logstash and Kibana To Centralize Logs On Ubuntu 14.04
Eso es todo por hoy. Feliz análisis y Felices fiestas!









{kind=link}